- 1
- 2
АДАПТИВНЫЙ ГЕНЕТИЧЕСКИЙ АЛГОРИТМ, ДЛЯ РАСПРЕДЕЛЕННЫХ СИСТЕМ С ПРОИЗВОЛЬНОЙ ТОПОЛОГИЕЙ
Введение
В настоящее время распределенные системы являются наиболее перспективным направлением развития параллельных систем. Для чего используются параллельные системы. Думаю, если вы читаете эту статью, то уже сами знаете направления, которые невозможны без них. Приведу несколько: • моделирование сложных процессов, • векторно-матричные вычисления, • обработка 3D графики(создание текстурных фильмов), • создание распределенных баз данных. Параллельные системы подразумевают использование одинаковых по параметрам процессоров, быстрых или даже полносвязных соединений, дорогое ПО. В противовес этому вы можете купить 4 персональных компьютера и создать систему, которая параллельно сможет обрабатывать данные. В чем недостаток параллельных и тем более распределенных систем — для корректной работы (распараллеливания) необходим адаптивный алгоритм, которому приходится решать NP-полную задачу планирования задач на ресурсы системы. Математического решения за конечное время в общем виде такие задачи не имеют. Поэтому для этих проблем используют эвристические подходы. Их можно разделить на три группы: списочные, генетические и кластерные. Данная работа посвящена рассмотрению генетических алгоритмов для задач назначения. Так как я не встречал больше каких либо аналогов своей работы, то перейду сразу к рассмотрению проблемы.Исходные данные для планирования
При решении проблемы планирования исходными данными являются: характеристика процессора, тип вычислительной системы, топология вычислительной системы, параллельный алгоритм и критерий эффективности. Будем рассматривать неоднородные вычислительные системы. Характеристиками процессора (процессорного элемента) являются: • производительность процессора (количество тактов в единицу времени); • количество физических каналов пересылки данных (линков); • скорость передачи данных по линкам (количество единиц информации в единицу времени) и возможность пересылки в разных направлениях (дуплексные и полудуплексные); • возможность одновременного выполнения вычислений и пересылок. Вычислительная система задастся в виде графа системы на котором Nп — номер процессора, Sп — скорость процессора в квантах вычислений, которые он может выполнить за один квант времени, Sл скорость линка, связи в количестве квантов данных, которые он может переслать за 1 квант времени. Дуплексная связь или не дуплексная здесь не указывается для облегчения объяснения. Задача задастся в виде процессов, показанных в виде графа, где Nз номер задачи, Tз — количество квантов времени, которые требуются задаче для выполнения, Tп — количество квантов времени, требуемых для пересылки.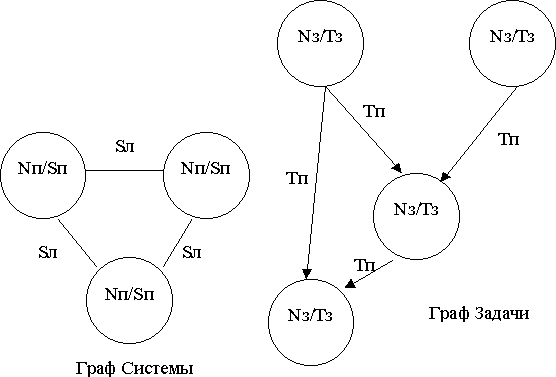
Основные этапы работы генетического алгоритма
Согласно выбранному критерию генетический алгоритм должен обеспечивать минимальное время выполнения указанных вычислительных задач на ВС заданной топологии Критическое время Tкритич — минимальное время выполнения параллельного алгоритма, которое не учитывает затрат при пересылках данных и таким образом является идеальным, но в большинстве случаев недостижимым из-за того, что в реальной ситуации не удается избежать пересылок данных. Исключениями могут быть те случаи, когда удается частично избежать пересылок посредством назначения связанных процессов, находящихся на критическом пути, на один и тот же процессор, а остальные пересылки выполнять без потери времени, зарезервированного за счет параллельного выполнения других процессов. С другой стороны, максимальное время выполнения алгоритма в любой системе — это время ее выполнения на одном процессоре Tпослед. В этом случае пересылки данных отсутствуют и это время определяется как сумма вычислительных сложностей каждого процесса алгоритма. Поэтому, величина реального минимального времени выполнения алгоритма Tреальн всегда находится в следующем диапазоне: Tкритич, Tреальн, Tпослед. Чтобы достигнуть минимального времени выполнения задачи в ВСРП, алгоритм планирования должен обеспечить минимальную суммарную задержку выполнения всех процессов.Функциональное описание самооптимизирующегося генетического алгоритма планирования произвольного графа задачи на произвольную структуру вычислительной системы
1. Генерируем случайным образом 100 генотипов планирования графа. И также 5 «лучших» — нужно для алгоритма.
2. Скрещивается каждый со случайно выбранной из генофонда (100 хромосом): Перебираются все геномы, каждому выбранному ищется пара случайным образом из текущих, проводим скрещивание каждой хромосомы с подобной. Пример дан внизу. 3. Производим мутации с определенной вероятностью. Происходит, если текущий геном подвержен мутации, случайное изменение значений отдельных участков(генов). Фактически перегенерация генотипа.

4. Преобразование генотипа в фенотип. На основании планировки, приоритетов пересылки и вычислений вычисляем время выполнения. • Производим сортировку по приоритетам всех пересылок в графе задачи. Приоритеты пересылок определяются по приоритетам задач для которых они нужны. • Производим сортировку вершин по их приоритетам. • Пока все вершины не выполнены производим: а. Ищем вершину не выполненную, для которой получены все данные и процессор которой не был занят при текущем событийном цикле. Затем выбираем время начала максимальным из времени начала вершины и времени процессора на котором будет выполнятся вершина. Выполняем если- время конца время начала + выполнение на текущем процессоре с определенной скоростью. Присваиваем время конца процессору, помечаем вершину как законченную. Маскируем процессор (для того, чтоб не выполнялись менее приоритетные вершины для которых получены данные) и производим пересылки. б. Пока не выполнены все пересылки вершины, то пересылаем текущую по матрице коммутативной маршрутизации(в матрице каждая ячейка представляет собой два поля
- 1
- 2